
E-Learning Video Enforcement Gone Wrong, Here's How I Fixed it.

This is not a technical article, nor a tutorial. This article explain a big-overview of my latest experience. Just want to share my experience on how I implement my security updates in my current company's E-Learning.
My company had a simple E-Learning Platform which people can take a course and watch video chapters. It can enforce students to finish some percentage (e.g. 80%) of watching video before they can proceed to the next chapters.
We had a client, and the client decided to ran a pentest, they found security issue regarding the video course, which they can tamper a request to our API and the video 'completed' in a second.
This article contain some sections.
- Existing Approach
- Existing Tradeoffs
- Goals
- New Approach: Back-End
- New Approach: Front-End
- New Security Concern
- New Tradeoffs
The Existing Approach
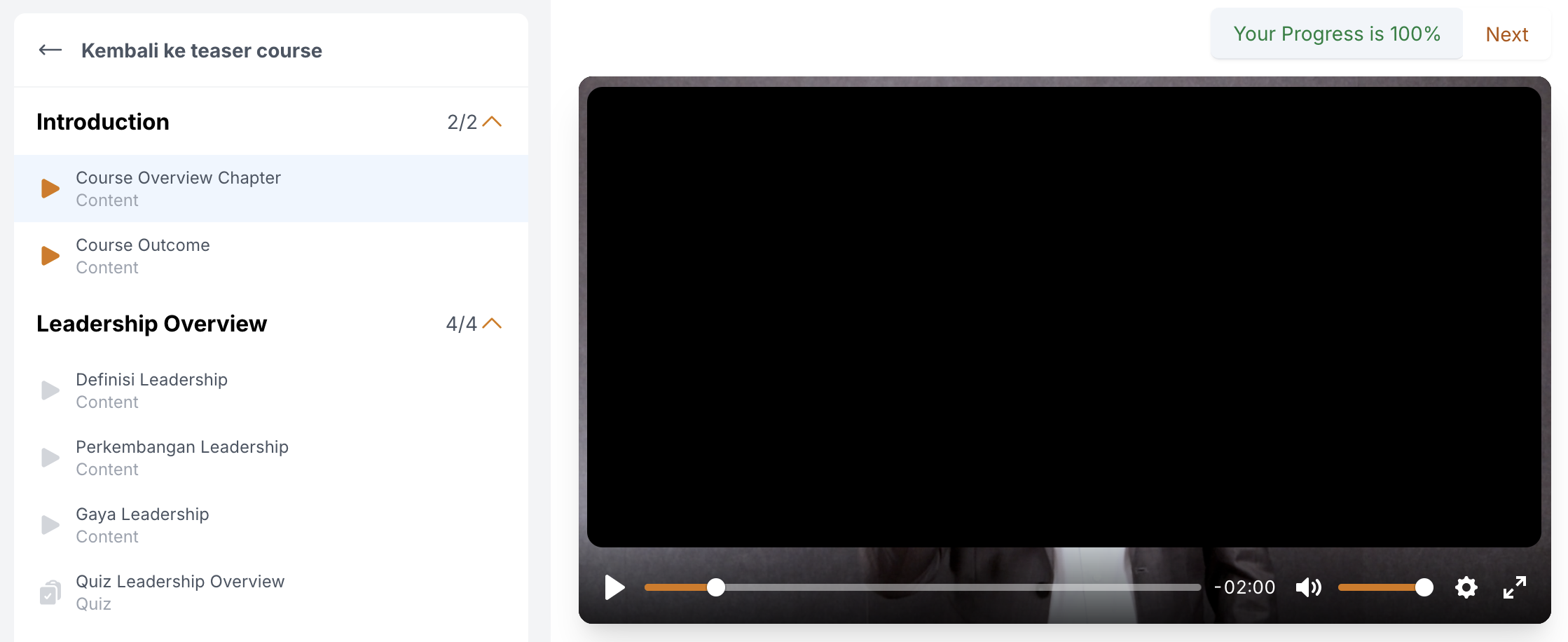
I was not the one developing this feature, so I started from analyzing what happened to our existing approach.
So, we use plyr as our video player library. Our video progression check was running in a client side. How it worked was so simple,
- We force people to watch without an ability to
seekthe time even a seconds - When
plyr.play– we sendcurrentTimeto an API call - When
plyr.timeupdate– every 10 seconds, we send step-2 periodically - Overtime, the client side will check if
currentTimealready 80% todurationor not, if yes, putis_done=truein the API request too.
What the API do?
- Receive a request of
currentTimewith additionalis_done - Save the
currentTimeinto a table along withis_doneif exists
A naively simple approach, but it work only if the user can not opening network console. 😈 – As you can see in Figure 1-2, the user's capabilities to navigate in the video are limited by only: play and stop the video.
Another thing to add context, the data structure was something like Figure 1-3, where the is_done was immediately saved into progress_done – that's why it was so easy to tamper the progress.

Here's my summary of concern in existing approach:
- One `GET` API did multiple things: Getting Progress and Updating Progress
- Progress's done defined at client-side instead of server-side
The Existing Tradeoffs
Bad user's experience (disabling seek) – user have no freedom on which time to watch in the video, they passively follow along, and unable to interact at all with the platform. Even 80% enforcement may fair enough, but the important content not always at the start of a video, it may at the end, right?
Security Issue/Cheating (client-side validation only) – some modern browser now, such as Firefox, provide a feature in Network Console, Edit and Resend a network call as you can see in Figure 1-4.
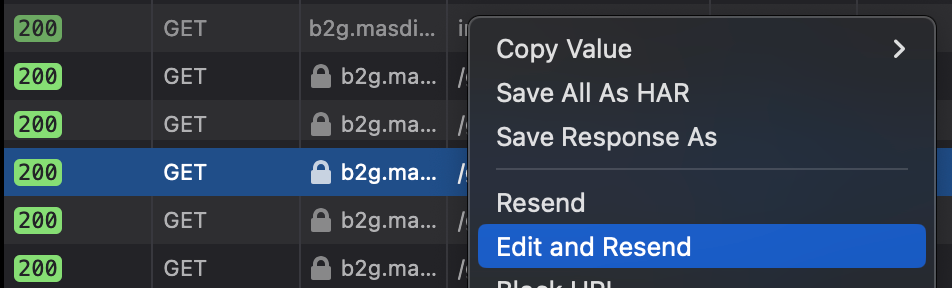
User can 'resend' new payload and put is_done=true and boom! You can skip a video chapter – do it again, and you can skip the other next videos. Fantastic.
No Metrics, No Observability – a naively simple approach as I mentioned before was having no observability and metrics. What it means?
If there's an issue with the video validation in user's side, how will you debug it? If there's a lot of unfinished dangling courses, how will you know which one from the video, content, or the software itself made it fail? How do your know if the user actively interacting with the content? But of course, we were not letting the user interacting at all.
Reflection & Goals
After understanding the existing approach, I should start somewhere, so I started to decide the goals.
- Fixing the Security Issue – this is my main goal, so I decided to make the validation in server-side, and minimize the hole in client-side.
- Better User's Experience – may not at best, but I want to make the user feels that they have freedom to watch which part of the video.
- Better Monitoring – decided to make a watching timestamps. With the timestamps log, I could validate the watching time to video duration, I could extract how long the user watch the video in overall, do they repeating some parts of the video? Or do they skipping some other parts in the video?
To get started, I started from breaking down the Back-End and how the new approach works, and then Front-End approach, and we'll discuss the security concern.
New Approach: Back-End
Seeing tradeoffs in existing approach, here's my checklists for the Back-End.
- Progress done should be defined by server-side instead of client-side
- So we need to add a new table to store the user's activity of watching the video, based on this new table, we should be able to define the progression
- Split the API responsibility: Check Progress and Updating Progress
So I started from making a diagram, I use Mermaid, embedded into my Markdown Editor in PHPStorm. I need to define first how the new table integrated with the existing structure and not breaking down the existing (my take: code changes should be compatible with previous version, so it can shipped incrementally to customers instead of shipping breaking changes).
So, I should expand the existing structure as shown in Figure 1-3 before, and added new table as logs to the VideoProgress as you can see in Figure 1-5 below.
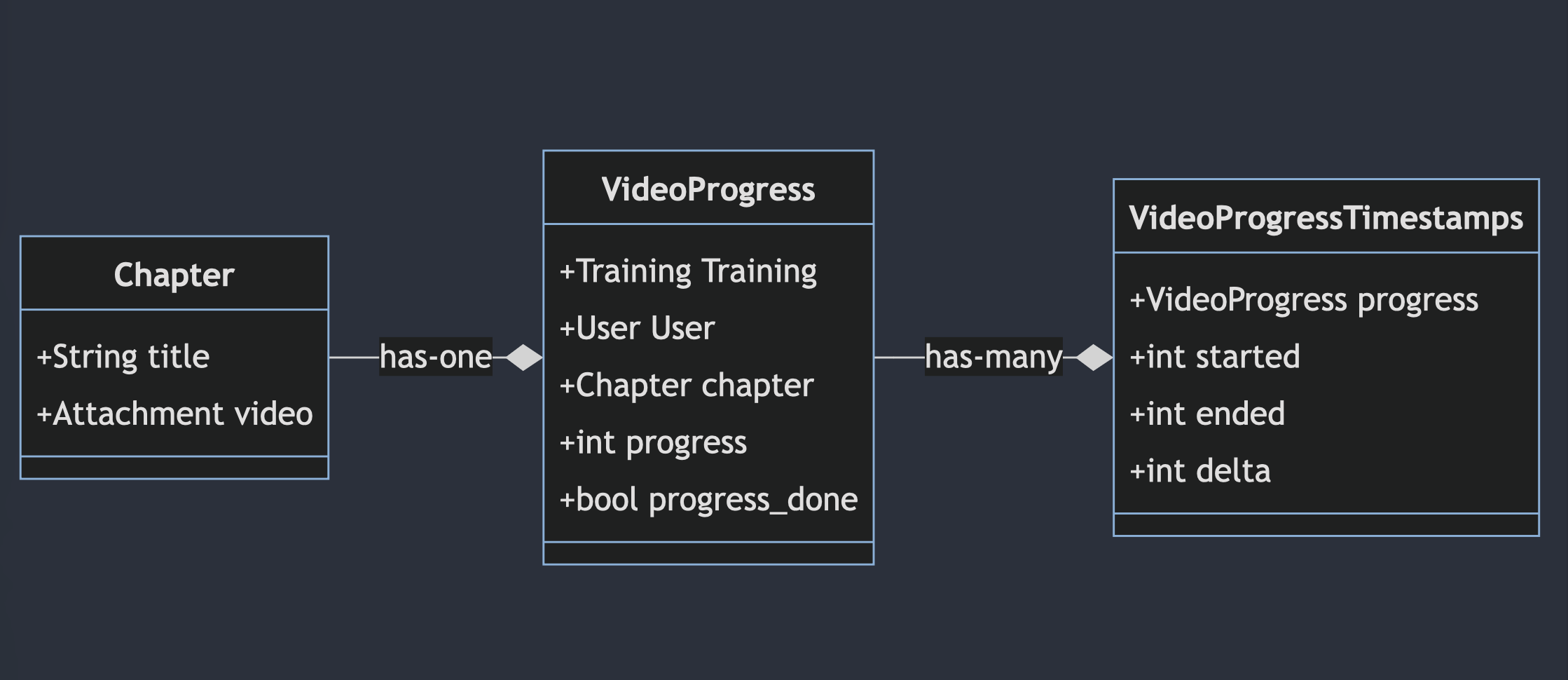
With this structure, I expect list of data as shown in Figure 1-6 below.
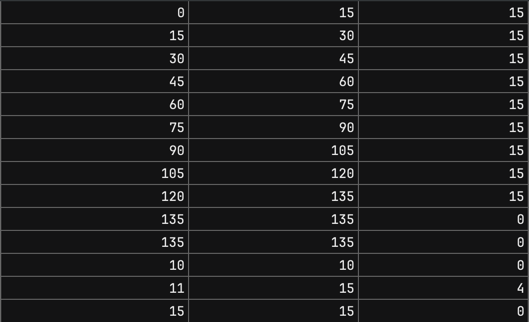
Here's the column breakdown:
- 1st - Started Time in Seconds (
stamp_started) - 2nd - Ended Time in Seconds (
stamp_ended) - 3rd - Delta Time in Seconds (
stamp_delta)
With additional table to record the progress timestamps (or seconds?), we later can define the 80% progression based on that recorded timestamps. The visualization of those logs should be something like Figure 1-7.

I see the expected future. Then, I planed for the API endpoints, which they should be like this.
POST /{course}/progress/record: this API will receivestamp_startedonly, from there, we created the timestamp log.POST /{course}/progress/recorded: this API will receivestamp_startedandstamp_ended, thestamp_startedwill work as identifier to search existing timestamps, if there's no such timestamp started with that, the API shouldcreatenew timestamp log.GET /{course}/progress/check: both API before, will dispatch a function (or queue) to update the VideoProgress (progress_done) based on available timestamps, we'll go further later on.
Now, we already split the API and make the API's design better
New Approach: Front-End
From a Front-End perspective, we need to call these APIs
POST /{course}/progress/recordPOST /{course}/progress/recordedGET /{course}/progress/check
The question was, when?
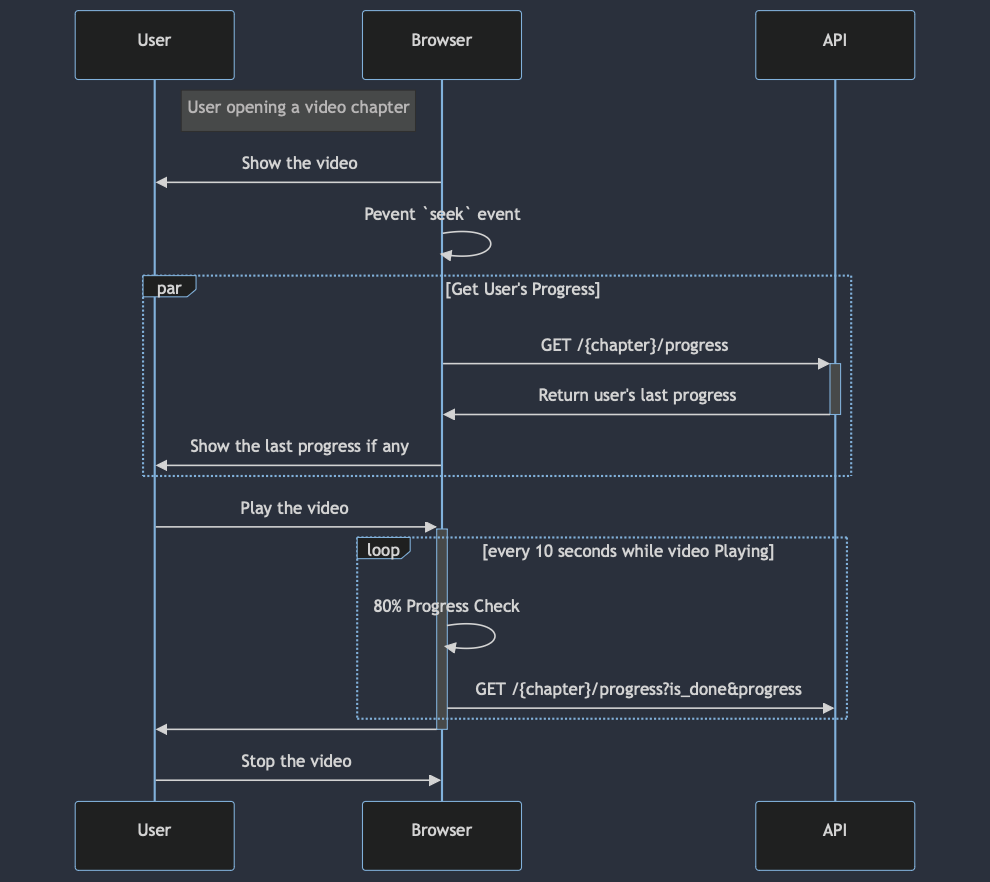
So, when the video being played, we should call record, and when the video stopped, we should call recorded, and if we want to check our progress, we call check – Easy right? But it's actually tricky, because we had forward and rewind.
Here's how I visualize the states (playing, paused, rewind, forward) of the video to understand it better as seen in Figure 1-8 below.
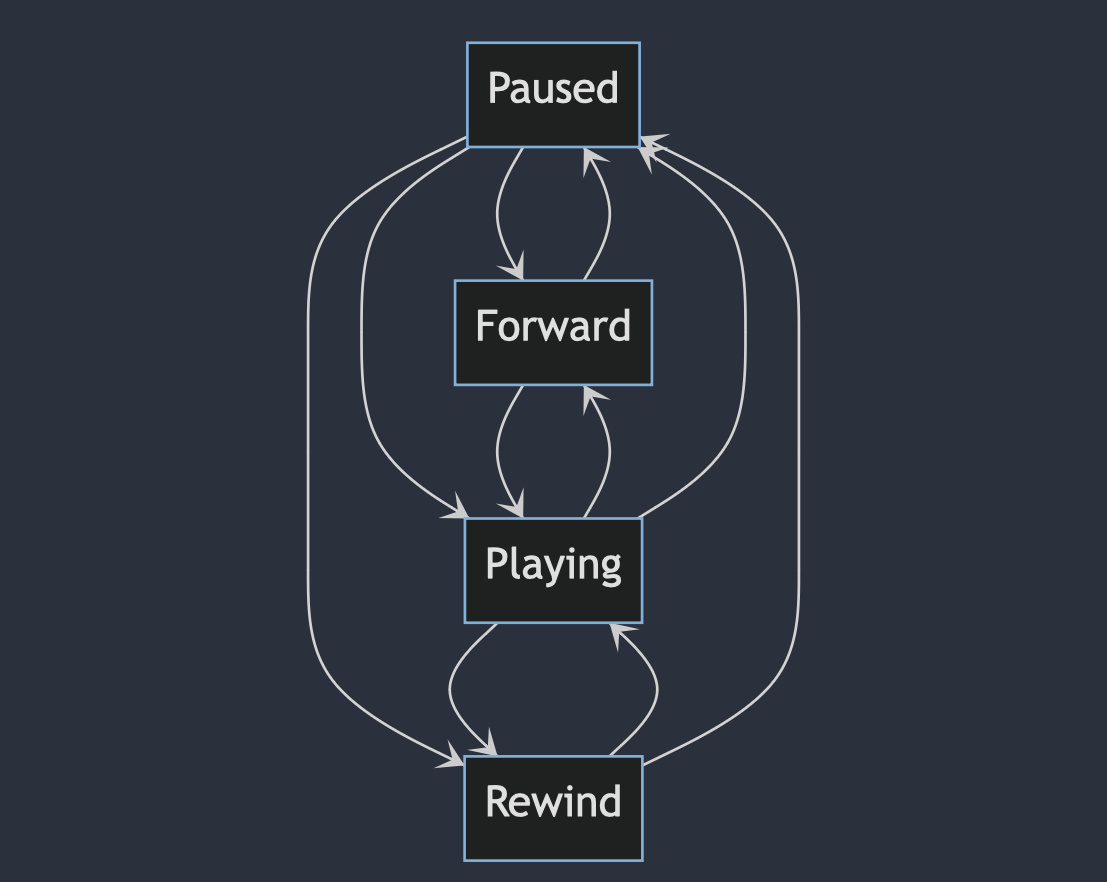
Based on illustration above, we can see that.
- From
pausedstate we canforward,rewind, andplaying - From
playingstate we canforward,rewind, andpaused
I need to combine how the video's state and the API recording's state work together. Figure 1-9 illustrate how I visualize it at first.
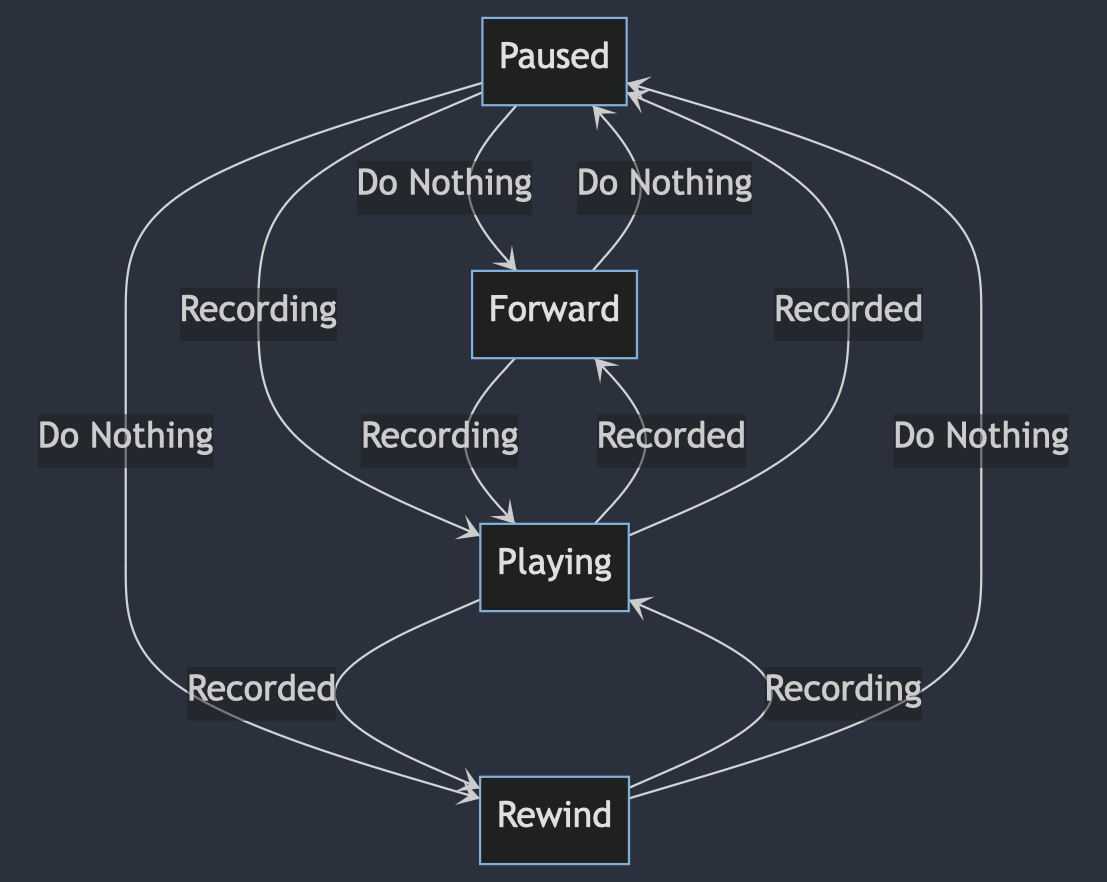
After some times, I realized that I can make it clearer. Diagram above was too bloated, so I split them as seen in Figure 1-10.
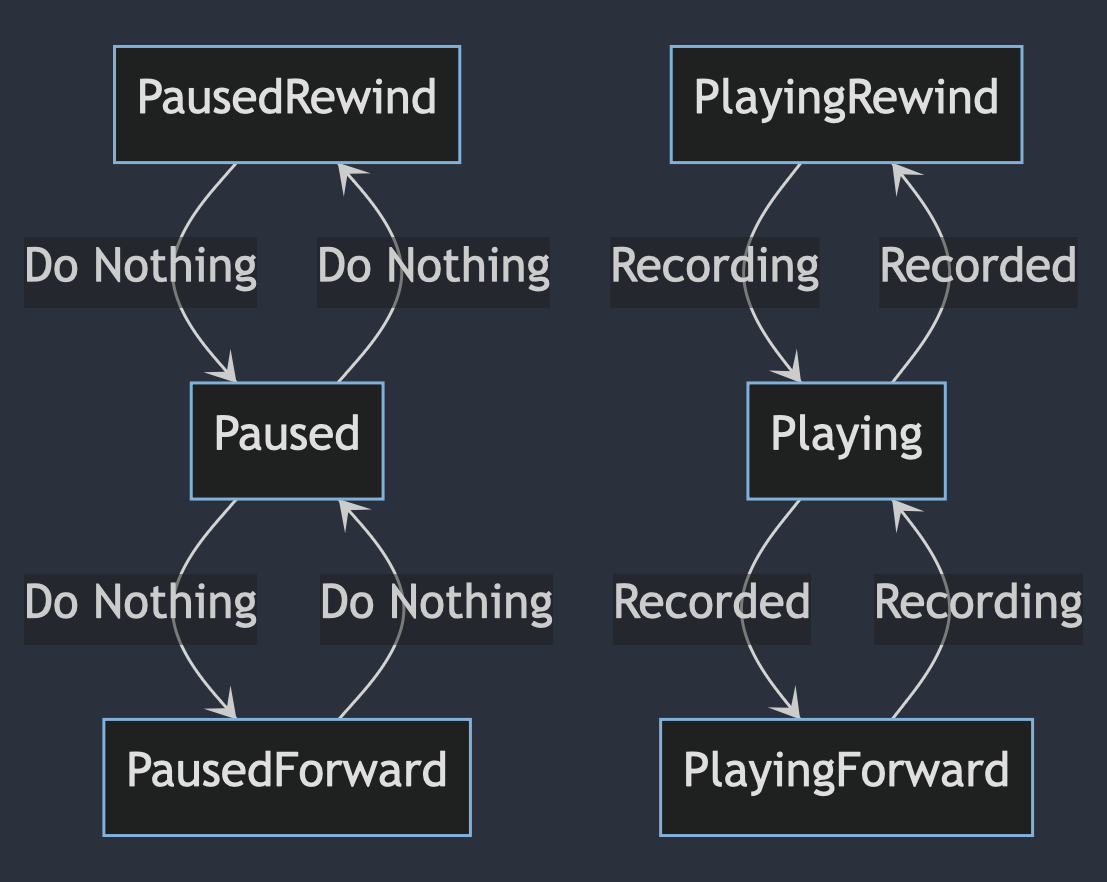
Same as the previous bloated one, but it now very clear that rewind and forward can be ignored while we in paused state or not-playing state. We only need to care what happen in playing state, this diagram save us from mental fatigue.
How about between playing and paused ? – of course it's more direct and obvious, here's how they connected.
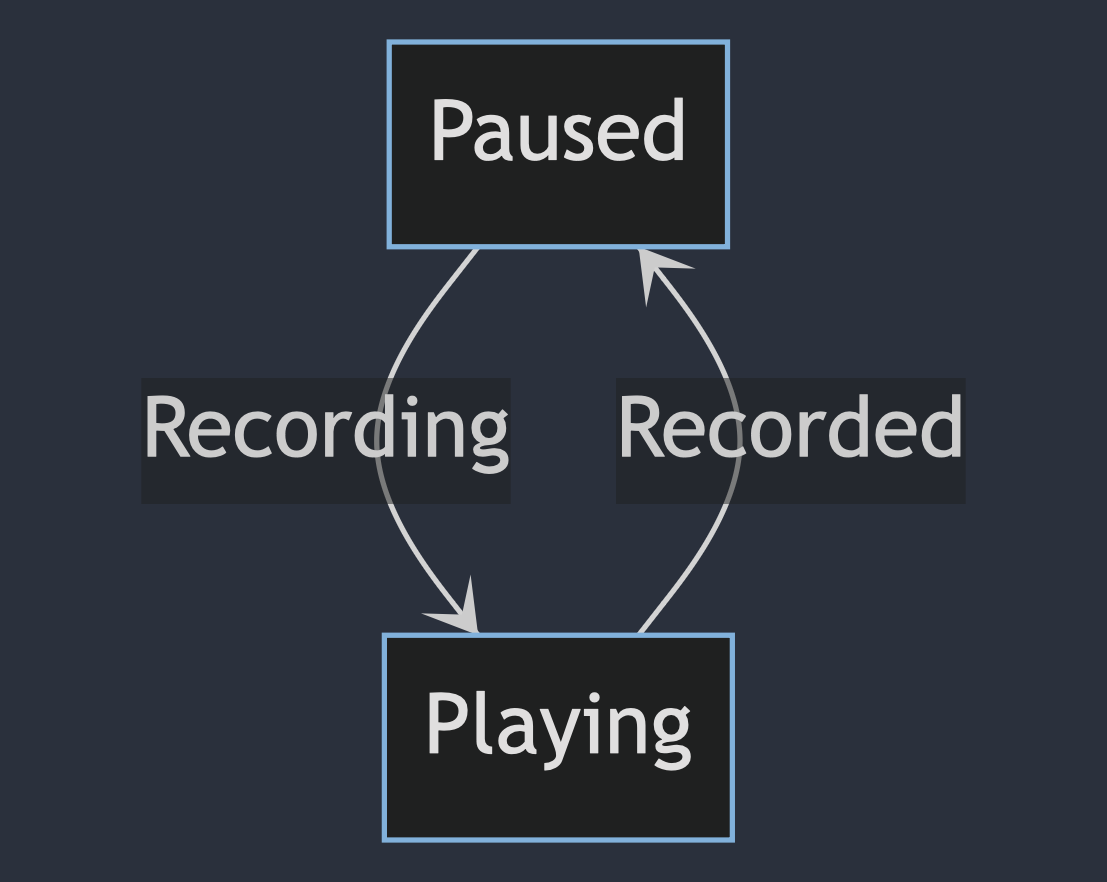
After understanding the when to call the provided APIs, we can implement it obviously. Here's how the JS pseudocode in our client-side.
let startedRecordingTime = 0
plyr.on('play', event => {
startedRecordingTime = plyr.currentTime
newProgressRecording(startedRecordingTime, ...)
})
plyr.on('seeked', event => {
if (plyr.playing) { // handle if playing: stop and new record
const newRecordingTime = plyr.currentTime
logProgressRecording(startedRecordingTime, plyr.currentTime, ...)
.finally(() => {
startedRecordingTime = newRecordingTime
newProgressRecording(startedRecordingTime, ...)
})
}
})
plyr.on('timeupdate', event => {
if (currentTime % 5 === 0) {
logProgressRecording(startedRecordingTime, plyr.currentTime, ...)
}
})With this,
- No more checking progress in client-side
- User not only able to
playandstop, but also navigate (seek)
Our front-end experience now better, security issue now minimized.
New Security Concern
Let's do a checkpoint here,
- We already split the API and make the API's design better
- We already make the user's experience better
- Security issue now minimized (yes, minimized?)
We now have records of the user's activities when they're watching video, and implement a progress checking logic in the server-side instead of client-side, is it now secure?
Let's say that a user play a video.
When a page opened, the video shown to the user, the user then play the video, an API call made, it sent startedRecordingTime=0 (the video started at 0s). Then we receive a record of data like this.

After 5 seconds (as you can see in the pseudocode), new log sent to server with startedRecordingTime is 0. The API will identify the received stamp_started to existing record in database.
- if the received
stamp_startedis 0, then the record exists (already made), the API will update thestamp_endedinstead of creating new log. - if the received
stamp_startedis not 0, then new record created withstamp_ended = stamp_started.
In this case, because stamp_started = 0 is exists in database, the existing record will be updated as you can see in Figure 1-13.

stamp_ended and stamp_delta updated.Go on to 10s.

Go on to 45s.

What's wrong then?
The API still can be tampered, let's assume that video's duration is 180s, when the user tampered the API call, they can send the stamp_ended to 180s, and the API assume that the user has watched the video until the end.
The server will accept it, and save the record like this.

The previous API explicitly insecure because the is_done parameter was open, but now the user can tamper the stamp_ended which make our API implicitly insecure now.
I'm not a security person itself, but my approach was to make it harder to cheating by adding abnormality check to the timestamps. So I limit the timestamps delta with no more than 15-25s, if so happen, there's an abnormality. Here's how the ideal timestamps shown in Figure 1-17, and how the ideal timestamps also can be shown in Figure 1-80.
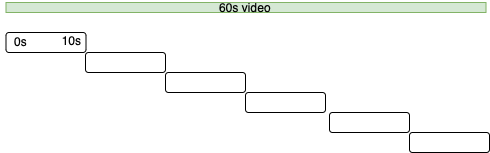

Breaking down the records into smaller pieces. This should be handled in the front-end, the API still able to accept the tampered request, but even it tampered, we can 'audit' better with this approach.
With above behavioral security measure (or what we call it?), we can add additional check if a timestamp's delta is more than 10s, the server should reject it.
So, if a user want to tamper their progress in 180s video (with 10s check), they should make at least 18 different requests.
New Tradeoffs
Of course there's a tradeoffs for the approach.
- Tampering is still possible, even it's now harder than before, but it's still possible to tamper the chapter's progress
- Logging is storage heavy, when there's 100 users watching a video of 120s, they at least (with 10s check) generates 12 * 10 = 1.200 records. If there's 20 videos in a course, that should be about 24.000 records for one course.
- User might be in abnormal activity accidentally in bad internet connection. A request can timeout, rejected, or else, and new request happened after next seconds milestone that might be incurring an abnormality.
Disclosure
My goal was to fix security issue, improve user's experience, and increase observability. User's experience improved by making the user able to seek into the video's time, move around and keep them engaging with the content. The observability just started from the data structure, logging, which can be improved more in the future. Unfortunately for the security issue, I was not yet conclude it as totally fixed, there's still some hole, but making it harder was the best I can do.